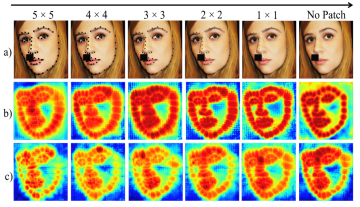
To address above issue, we propose a novel image augmentation technique, specifically designed for the FLD task to enhance the model’s understanding of facial structures. To learn facial structures effectively, we try to leverage the ground truth landmark coordinates as an inductive bias for facial structure. To this end, we introduce n×n black patches around the landmark locations in the training images, gradually reducing them over the epoch and then completely removing them for the rest of the training, as illustrated in Figure 1. Since the patches cover key semantic regions of the face, e.g., eyes, nose, lips and jawline, when the model learns to predict these patches, it is able to learn the entire facial structure significantly better, as compared to an architecture without this inductive bias. One could view this augmentation technique as similar to Curriculum Learning (CL) [1], a strategy that trains a machine learning model from simpler data to more difficult data, mimicking the meaningful order found in human-designed learning curricula.
Figure 1: In row (a), 5×5 black patches are created around the landmark joints (along with other standard augmentations) in the initial epochs and reduced over the epochs. Rows (b) and (c) show corresponding GradCAM-based saliency maps of the network’s last layer with and without FiFA, respectively. It is clearly seen that activations are more prominent around the desired landmarks when FiFA is used as additional augmentation.
To effectively utilize the newly proposed augmentation technique, we employ a Siamese architecture-based training mechanism with a Deep Canonical Correlation Analysis (DCCA)-based loss to achieve collective learning of high-level feature representations from two different views of the input images. We also employ a Transformer + CNN-based network with a custom hourglass module as the robust backbone for the Siamese framework. Our approach outperforms existing state-of-the-art approaches across various benchmark datasets both quantitatively and qualitatively as shown in Figure 2.
We performed extensive experimentation and ablation studies to validate the effectiveness of the proposed approach. Our method shows significant improvements over prior works on the benchmark datasets COFW, AFLW, 300W, WFLW. One of the benefits of this approach is that it is network independent and can be extended beyond Facial Landmark Detection task.