Nirmesh Shah, Senior Research Scientist at Sony Research India, educates us about the wide array of possibilities using generative models and that while they have several applications in the multimedia industry, they do not come without their share of caveats.
The key goal of generative models is to estimate the density of the large amount of data collected in some domain and then generate new data very similar to it. This can be primarily achieved in two ways, explicit and implicit. Explicit density models define explicit density functions and estimate parameters of this function during training. On the other hand, implicit density models define a stochastic procedure that can directly generate the data. PixelCNN, pixelRNN, variational autoencoders (VAEs), energy-based generative models, flow-based generative models come under the category of explicit models. Generative adversarial networks (GANs), markov chain-based models come under the category of implicit models.
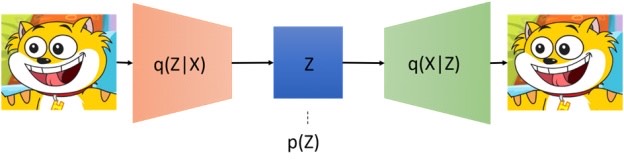
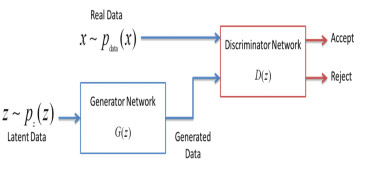
In VAEs, instead of directly extracting the latent features from the input data, we are trying to represent this problem in the framework of probabilistic graphical models. Basically, we are maximizing a lower bound on the log likelihood of data. On the other hand, GAN consists of two components, generator, and discriminator. The goal of the former is to generate data and the goal of the latter is to check whether data is coming from the true data distribution or model distribution (i.e., the generated sample is real or fake). Whenever a discriminator notices a difference between two distributions, the generator will adjust its parameters further to generate more realistic samples via reducing the distance between the two distributions. Both methods have their pros and cons. For instance, GANs can produce shared and very realistic data but are very hard to train. On the other hand, training, and inference of VAEs are sophisticated, but they produce blurry samples. Still, most of the approaches have overcome their limitations in the last couple of years and are now able to generate very realistic samples.
When it comes to the audio side, text-to-speech (TTS) technologies are used to synthesize any written text to different languages. Also, voice cloning, and voice conversion technologies can alter perceived speaker identity and/or a style of any source audio speech signal from any source speaker into desired target speaker. Similarly, image-to-image and video-to-video style conversion techniques are used to modify source image or video frames into desired target image or video frames to change facial characteristics, lip movements, etc. to alter any video. In core, all these technologies use deep generative models. These artificial video generation techniques are popularly known as Deep Fakes.
[1] Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
[2] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems 27 (2014).