Speech processing technologies such as voice conversion (VC) and automatic speech recognition (ASR) have dramatically improved in the past decade owing to the advancements in deep learning technologies. However, the task of training these models remains challenging on low resource domains as they suffer from over-fitting and do not generalize well for practical applications.
In this paper, we propose to iteratively improve a voice conversion model along with an automatic speech recognition model.
As VC models often rely on ASR model for extracting content features or imposing content consistency loss, degradation of ASR directly affects the quality of VC models. On the other hand, to improve the generalization capability of ASR model, a variety of data augmentation techniques have been proposed with voice conversion being one of them.
This creates a causality dilemma, wherein poor quality of ASR model affects VC model training which in turn leads to low quality data augmentation for training ASR models. Conversely, improving the ASR model should lead to better VC models, which should produce better data augmentation samples for improving the ASR models. Motivated from this, in this work we propose to iteratively improve the ASR model by using the VC model as a data augmentation method for training the ASR and simultaneously improve the VC model by using the ASR model for linguistic content preservation.
Proposed Method
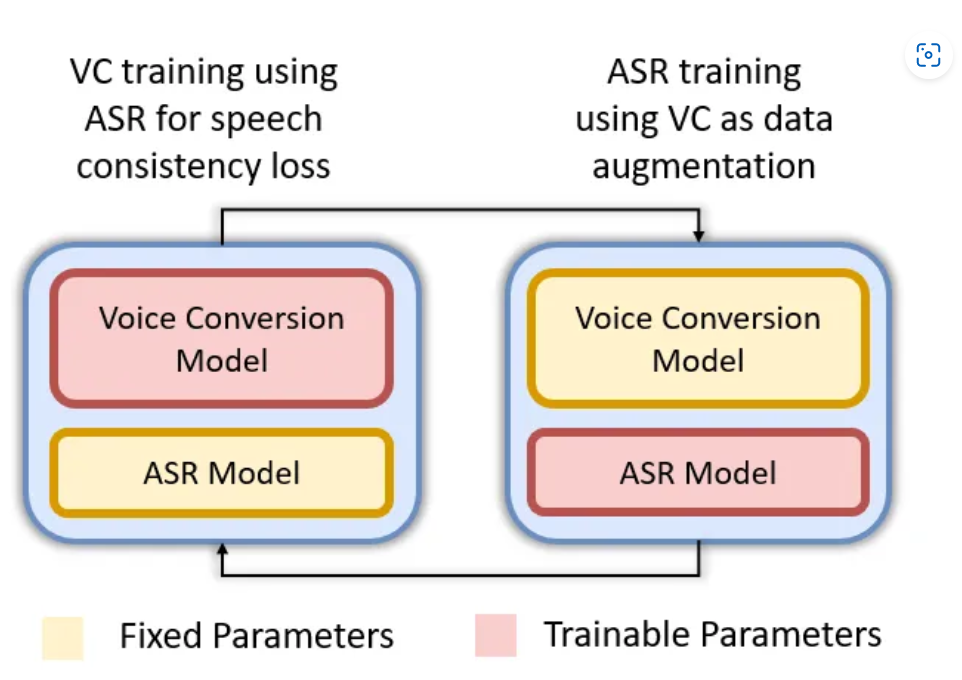
Figure 1: Overview of our proposed method. We first train an ASR model and a VC model with a default training regime. Then using the trained VC model as data augmentation for the ASR model, we further improve the ASR model. The updated ASR model is further used in the training of an improved VC model. This step is repeated until convergence of both the ASR and VC models.
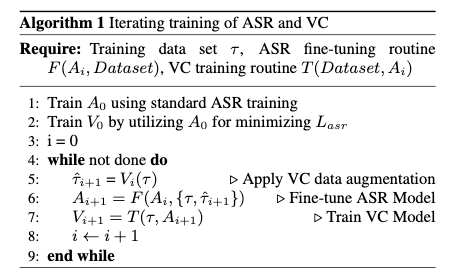
The proposed iterative training framework is illustrated in Figure 1 and its pseudo code is shown in Algorithm 1.
Algorithm 1: Iterative training of ASR and VC models
Results and Experiments
For the results and experiments, we refer the reader to our paper which contains the detailed experimental details along with the insights that we drew from the experiments. https://arxiv.org/pdf/2305.15055.pdf
Conclusions
We present a novel iterative framework for improving voice conversion models and automatic speech recognition models on low resource domains and verify its applications on the Hindi speech domain and English singing domain. We show improved speech preservation and MOS quality of the converted samples on voice conversion tasks as well as improved the word error rate on ASR tasks using this framework.
Future work includes further improving the content preservation of the one-shot VC models so as to bring WER of the VC converted samples closer to the WER on the ground truth samples which would also lead to better MOS quality. We would also like to investigate combining the ASR and VC training in an end-to-end system.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: