In this blog, Tushar Prakash breaks down the paper titled ‘CR-SoRec: BERT driven Consistency Regularization for Social Recommendation’ which was accepted at RECSYS-23 Conference, hosted in Singapore between 18th-22nd September 2023.
In this blog, Tushar Prakash summarises the paper titled ‘CR-SoRec: BERT driven Consistency Regularisation for Social Recommendation’ co-authored by Raksha Jalan, Brijraj Singh, Naoyuki Onoe which was accepted at the Recommender Systems 2023 (RecSys) Conference, hosted in Singapore between 18th-22nd September 2023.
In the real world, we often ask our friends for various recommendations. With the rise of social media, we can now do the same with our online connections. Social recommendations combine social connections with user-item interactions to give better recommendations. However, current methods have two limitations: they don’t fully explore the complex relationships between neighbours’ influences on user preferences, and they are prone to overfitting due to limited user-item interaction records.
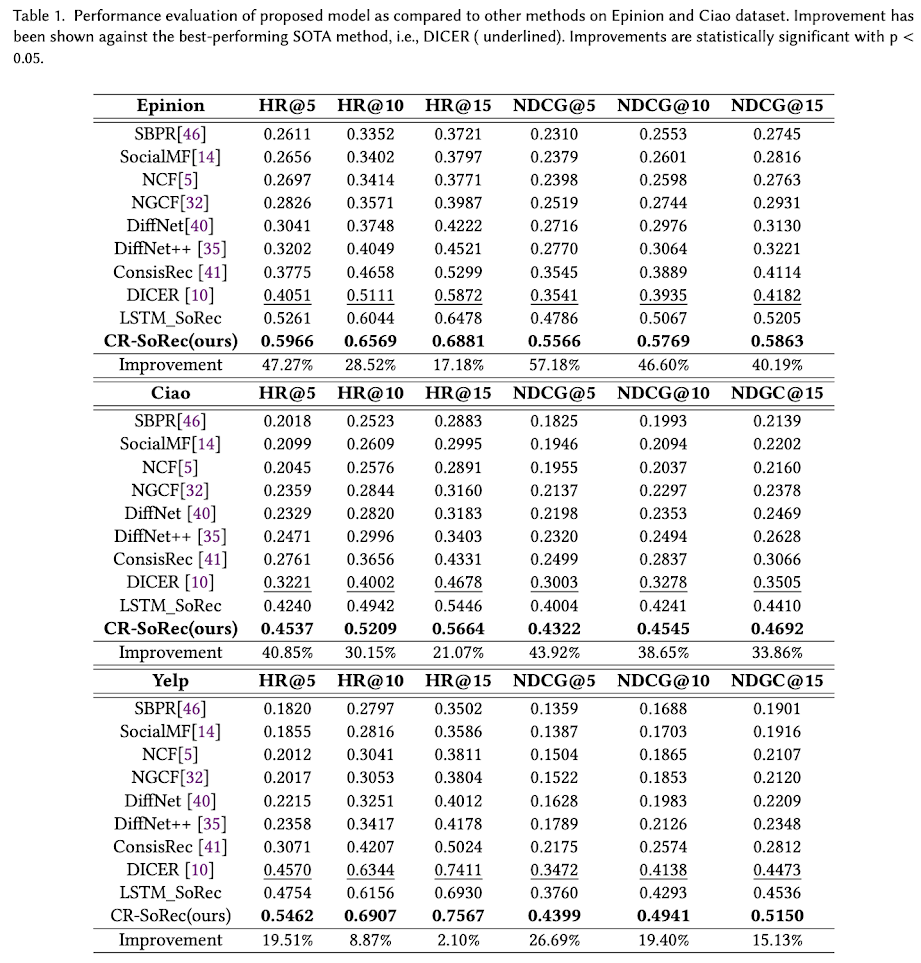
To solve these problems, we propose a new framework called CR-SoRec. This framework uses BERT and consistency regularization to learn context-aware user and item embeddings with neighbourhood sampling. It also leverages diverse perspectives to make the most of the available data. Our model aims to predict what item a user will interact with next based on their behaviour and social connections. Experimental results show that it outperforms previous work by a significant margin and defines a new state-of-the-art. We also conduct extensive experiments to analyse the proposed method.
Today, many e-commerce and online platforms have doubled down as social media platforms. For instance, Amazon’s “Watch Party” and Spotify’s “Blend” allows users to invite friends to watch content and share playlists.
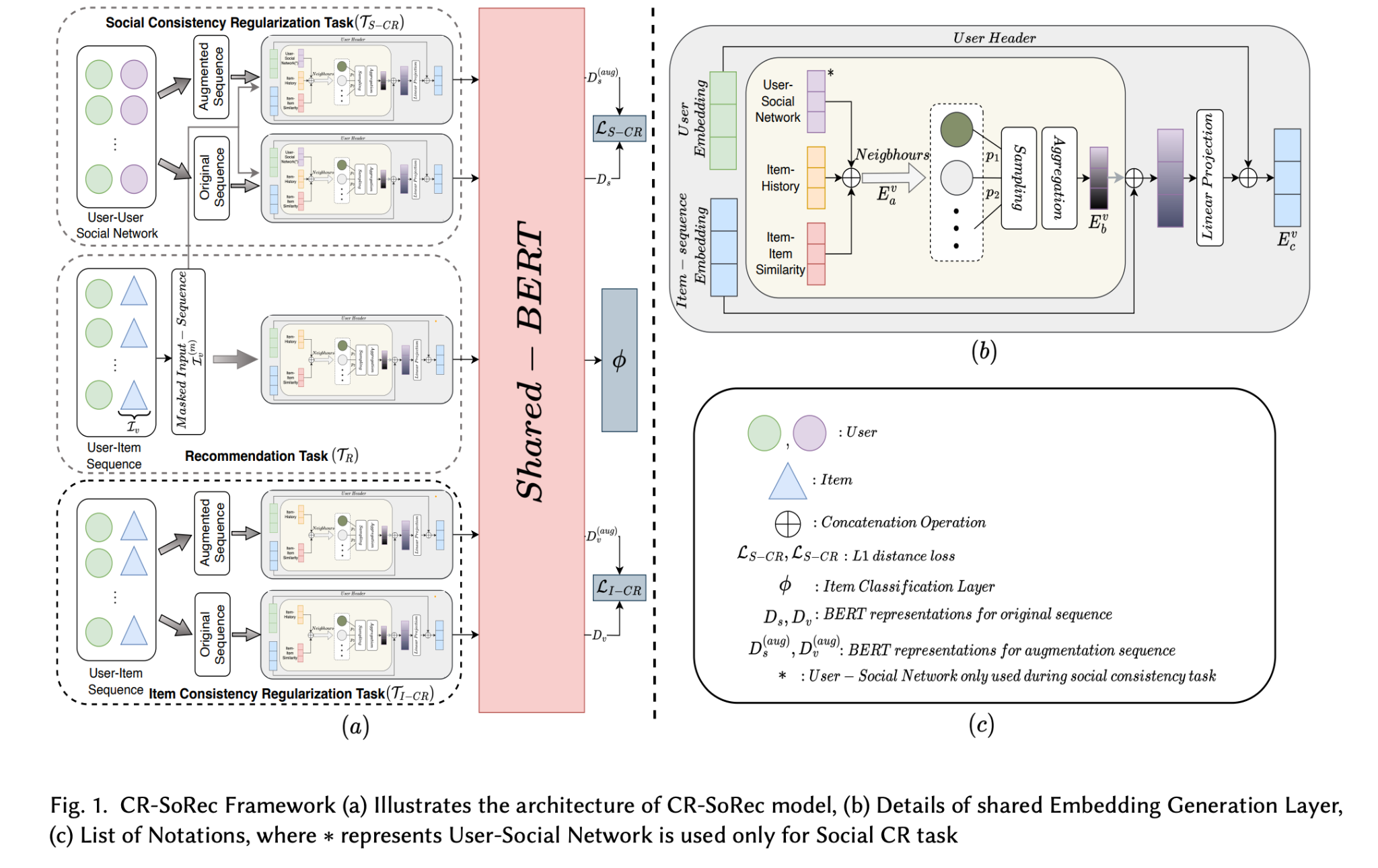
To improve such recommendation systems, it is important to incorporate social interactions into the model. However, high-order social relations make it challenging to extract relevant data for modelling user preferences. Our proposed framework, CR-SoRec, uses BERT and a Consistency Regularization Framework to efficiently learn user-item and user-user social representations. This is achieved by generating robust user-item interactions representation through user header with neighbourhood sampling. The proposed method also helps to eliminate insignificant signal from user-item interaction history. Data augmentation is performed to improve data diversity and the model’s robustness. The proposed network is trained by minimizing a combination of three types of losses. The main contributions of the paper include proposing a novel way to learn User/Item representations based on neighbourhood sampling in conjunction with BERT, designing two novel Consistency Regularization (CR) tasks- Item CR and Social CR, and proposing a new way to utilize social connection and user-item interactions with CR to enhance social recommendation performance.
Studies on social recommendation have shown a positive correlation between user social behaviour and item interactions. To capture this correlation, we propose enriching user and item embeddings with influential neighbours through neighbourhood sampling.
In the recommendation task, we are given a sequence of items that a user has interacted with. To generate a training sample, we randomly mask some items in the sequence using the classical Cloze task. The entire process of embedding generation with neighbourhood sampling is presented in Algorithm 1.
We perform neighbourhood sampling using a multinomial distribution, which incorporates information from the most influential neighbours. To bring similar user-item pairs closer in the embedding space, we introduce a user header that generates the user embedding E(u). In Algorithm 1, item-user interaction history (H𝑣𝑢) consists of a list of all users who have interacted with item 𝑣𝑖 in the past, while item-item similarity (S𝑣𝑣) represents similar items that have more than 50% of common users.
This task involves passing the original input sequence and its augmented version through BERT, after generating embeddings from the embedding layer. BERT provides distinct representations for both versions of the input sequence. Finally, a penalty loss is employed to minimize their L1 distance, thus enforcing similarity between the two representations as described in Algorithm 2.
This task involves passing the original input sequence and its augmented version through BERT, after generating embeddings from the embedding layer. BERT provides distinct representations for both versions of the input sequence. Finally, a penalty loss is employed to minimize their L1 distance, thus enforcing similarity between the two representations as described in Algorithm 2.
Note: The input sequence used in this task is not masked.
The proposed model is trained by jointly minimizing the cross-entropy loss for the recommendation task, and two different L1 losses for both consistency tasks. The figure 1 illustrates the overall workflow of the proposed model.

This research introduces a novel framework termed “BERT-driven Consistency Regularization for Social Recommendation” (CR-SoRec). We have demonstrated the importance of integrating user context and neighbourhood sampling alongside BERT to create a comprehensive representation for Social Recommendation.
Within the CR-SoRec framework, BERT contributes by considering bidirectional contexts when predicting forthcoming user-item interactions. In addition to this, we have proposed an inventive approach to enhance the model’s performance. This involves integrating diverse perspectives of user-item interactions and users’ social connections within the Consistency Regularization framework through two tasks: Item CR task and Social CR task.
Our model consistently outperforms the leading social recommendation algorithms in various experiments across all datasets, highlighting its superiority.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: