How can babies recognize any cow if we show just a few drawings of cows? How can humans learn to drive a car in about 20 hours of practice with very little supervision?
The short answer is that we rely on the previously acquired background knowledge of how the world works by observations. We observe the world, act on it, observe again, and build hypotheses to explain how our actions change our environment by trial and error. Such common-sense ability is taken for granted in humans but has remained an open challenge in AI research since its inception.
“Self-supervised learning is one of the most promising ways to build background knowledge and approximate a form of common sense in AI systems”
Self-supervised learning enables AI systems to learn from orders of magnitude more data, which is important to recognize and understand patterns.
What is self-supervised learning and why is it needed?
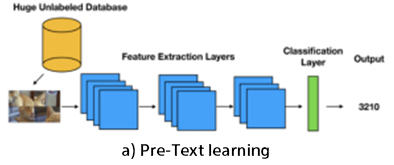
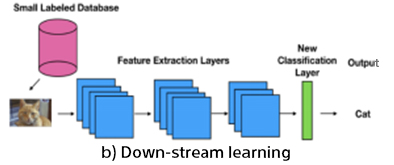
Getting good quality labeled data is an expensive and time-consuming task, especially for complex tasks where more detailed annotations are desired. On the other hand, the unlabeled data is readily available in abundance. Self-supervised learning provides a promising alternative, where the data itself provides the supervision for a learning algorithm. The motivation behind this is to learn useful representations of the data from an unlabelled pool using self-supervision first (i.e., pre-text task) and then fine-tune the representations with few labels for the supervised downstream task.
Let’s understand this with one toy example.
Our downstream task is image classification, where we want to classify images into the correct category (dog, cat, horse, etc..).
Assume we only have 1000 labeled images, which proves to be too few samples for the neural network to generalize well. Instead of initiating a new labeling effort, self-supervised learning will help let out neural networks first to learn some general features of images before going with fine-tuning on the target classification task.
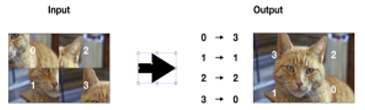
Figure 1 shows one example using the jigsaw puzzle to learn representations. Particular puzzle images are created by shuffling the patches of input images and then applied to the pretext network, where it is trained to determine the relative position of patches. Here, the network will learn some general features of the distribution of images. Once we have a trained neural network, what we are really interested in is the feature extraction layers. This is where the lower level and more task-agnostic features will reside and we will re-purpose them for our downstream task. Combining these feature extraction layers with task-dependent final layers, we get our target model to classify the objects. In this way, the classification task can be carried out with good performance even with less human-annotated data.
Siamese architecture based self-supervised learning
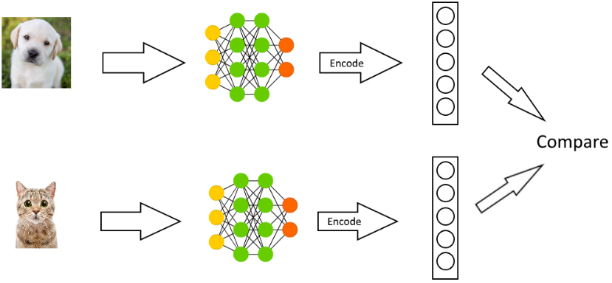
Recent advances in self-supervised learning models have been designed based on Siamese neural networks whose design has been illustrated in Figure 2.
It consists of two branches with a shared encoder on each side, and its similarity metric is computed based on two representations from the two encoders. Its main purpose is to learn representations such that two representations are similar if two input images belong to the same class and two representations are dissimilar if two input images belong to the different classes.
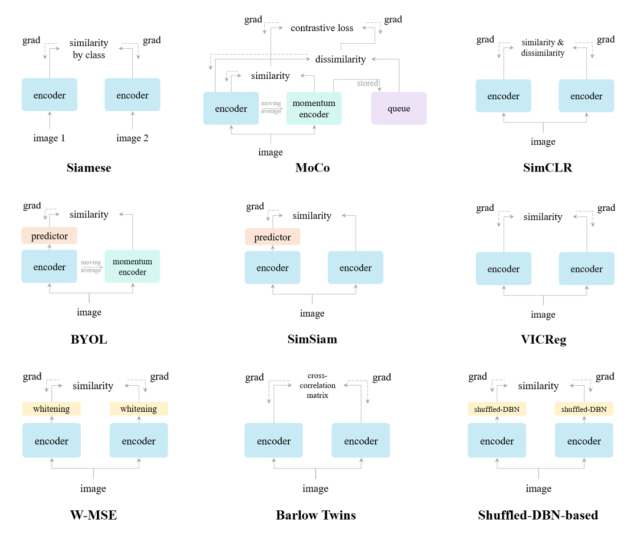
Based on this Siamese network design, many self-supervised learning-based models have been proposed recently. A brief comparison of these models is depicted in Figure 3.
Here, an image is taken, apply random transformations to get a pair of two augmented images which are passed through an encoder to get representations. The task is to maximize the similarity between these two representations for the same image.
Application of Self-Supervised Learning
Self-supervised learning has endless applications in healthcare, editing, forecasting, driving, chatbots, video editing, transforming, and data recognition. The following are among the most primary applications for self-supervised learning:
Similar to human vision, self-supervised learning is learned based on background knowledge and approximates a form of common sense in AI systems. Self-supervised learning aims to learn good representations from unlabelled data. This reduces the need to depend on vast amounts of data like in the case of supervised learning. However, self-supervised learning has a few limitations such as time taken to build unlabelled models and the occurrence of inaccuracy in labeling which may cause errors in the results. Besides this, self-supervised learning-based methods have been achieving great success and obtaining good performance that is close to supervised models on some computer vision tasks.