20th August 2024

Overview of proposed framework
Vishal Chudasama summarises paper titled Cross-Modal Fusion and Attention Mechanism for Weakly Supervised Video Anomaly Detection co-authored by Ayush Ghadiya, Purbayan Kar ,Vishal Chudasama, Pankaj Wasnik accepted at the CVPR 2024 7th MULA Workshop | June 2024
Weakly supervised video anomaly detection (WS-VAD) is essential for identifying anomalous events in videos, such as violence and nudity, using minimal labelling effort. This task is crucial for content moderation and surveillance applications, ensuring safer online environments and effective security systems. While deep learning and multi-model learning methods have significantly improved WS-VAD tasks’ performance, they still face many significant challenges. One of the challenges in WS-VAD is the imbalanced modality information and the inconsistent discrimination between normal and abnormal features. This imbalance often hampers the detection accuracy, as the model struggles to appropriately weigh the contributions of different modalities (audio and visual).
To address these issues, we introduce two novel components

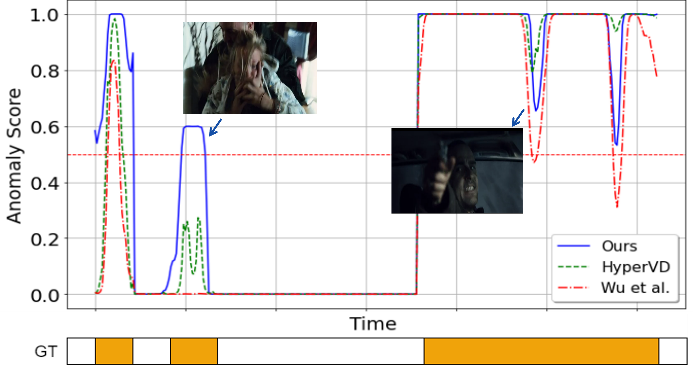
We present a new WS-VAD framework with a Cross-modal Fusion Adapter (CFA) module and a Hyperbolic Lorentzian Graph Attention (HLGAtt) module to detect anomaly events such as violence and nudity accurately. The proposed CFA module addresses the imbalanced modality information issue and effectively facilitates multi-modal interaction by dynamically selecting the relevant audio features with corresponding visual features. Additionally, the proposed HLGAtt module captures the hierarchical relationships within normal and abnormal representations, thereby improving the accuracy of separating normal and abnormal features. The proposed framework outperforms existing state-of-the-art methods on violence and nudity detection tasks.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: Open Innovation with Sony R&D – Sony Research India